
Instalando/configurando cluster MYSQL (galera) multi master com alta disponibilidade (HA) e balanceamento de carga – Pronto para produção
Fala aeees seus devs marotos, depois de MUITO tempo venho eu mais uma vez trazer aquele tutorial MAROTÍSSIMO e deveras interessante para os amigos que querem montar um ambiente clusterizado e com alta disponibilidade do SGBD MYSQL, setup este que vai ficar prontinho para colocar em produção, este setup é bem parecido com o que uso na produção dos meus sistemas hoje, e desde que eu o implementei eu não sei o que é downtime de banco de dados.
Lá em 2008 (ano em que eu aluguei o primeiro servidor do que eu chamaria de GuidiHost) quando eu comecei essa brincadeira de servidores, nos meus tempos de hospedar IRCD, IrcCOP e tal, a vida era muito mais complicada, não existia um ferramental tão grande pra te ajudar a montar um ambiente de alta disponibilidade, fora que o custo era bem maior e um dos meios de conseguir fazer as coisas era na base da tentativa e erro, graças a Deus de uns tempos pra cá tudo ficou mais fácil.
Vou lembrar que o objetivo deste post é ser DIDÁTICO, o foco é aprender a ter esse setup em servidores VPS ou bare metal em casos onde seja necessário ter este setup fora de serviços como Amazon RDS, Azure SQL ou “insira o nome de um grande player de cloud aqui”, então, não cabe aqui a discussão se seria melhor colocar em um dos serviços de banco relacional destes players, você que é DEVERAS manjador de AWS poderia dizer: – Não seria mais prático colocar no Amazon RDS em implantação Multi AZ? Responder essa pergunta tem alguns poréns, sendo um deles o fator custo, além do mais, qual seria a graça?
Pra quem achou que eu faria isso digitando no terminal SSH IGUAL UM LOKO ou que usaria Puppet, Cheff ou Ansible com alguma recipe ou playbook, está deveras enganado, eu sou maluco, mas nem tanto, não me leve a mal, eu amo esses gerenciadores de configuração, mas fazer isso por eles seria um trabalhinho de corno, dito isso, vou usar uma ferramenta super ultra mega fodástica chamada ClusterControl.
ClusterControl é o Santo Graaal que vai economizar MUITO do nosso tempo para subir o setup desse tutorial, ele tem a versão community que é totalmente gratuita e você ainda pode usar 30 dias de TRIAL pra conhecer melhor todas as funcionalidades que ele tem a oferecer.
Disclaimer
Um detalhe que com certeza não vai passar despercebido pelos senhores é que no meio do tutorial o IP das máquinas muda, isso aconteceu pois esse post foi sendo escrito em partes e eu acabei recriando os droplets no meio dele e fiquei com preguiça de atualizar as imagens, se ficar algum dúvida, estou a disposição para elucidar… ou não.
Pré-requisitos
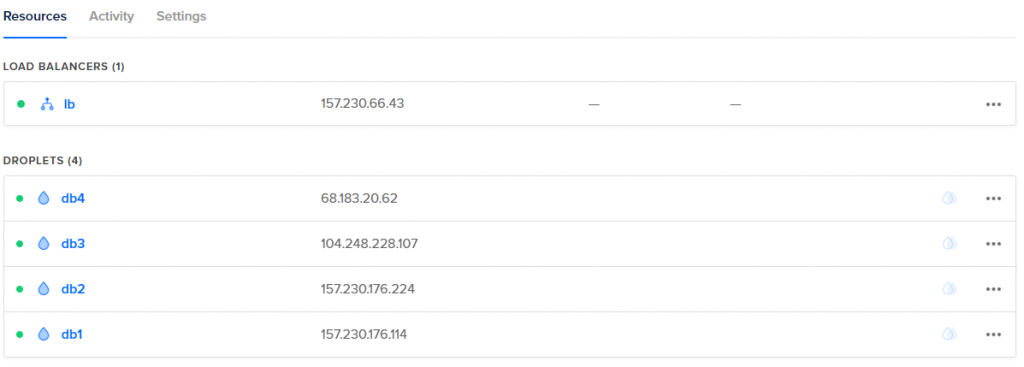
Pra essa brincadeira vamos precisar de 4 máquinas com configuração de no mínimo 1 vCore e 1GB de RAM (para o Cluster Control eu recomendaria 2GB, se quiser fazer com 1GB, faça isso ciente que você vai operar com 80% da RAM em uso), além de 15GB de espaço em disco, o sistema que vou usar vai ser CentOS 7.5 mas se você quer usar outra Distro, fique à vontade, eu criei 4 droplets na Digital Ocean todos eles com private network habilitado, além de um balanceador de carga que fica na frente do db2, db3 e db4 que serão os nós do nosso cluster, saliento que pode ser usado qualquer outro provider que forneça os recursos que vamos utilizar aqui.
Se quiser fazer essa brincadeira na Digital Ocean DE GRÁTIS basta clicar no meu link de afiliado aqui e ganhar $100 de crédito para usar lá, isso mesmo, $100 de crédito para usar em até 60 dias, DE GRAÇA e sem letras miúdas, é criar o cadastro, usar e ser feliz.
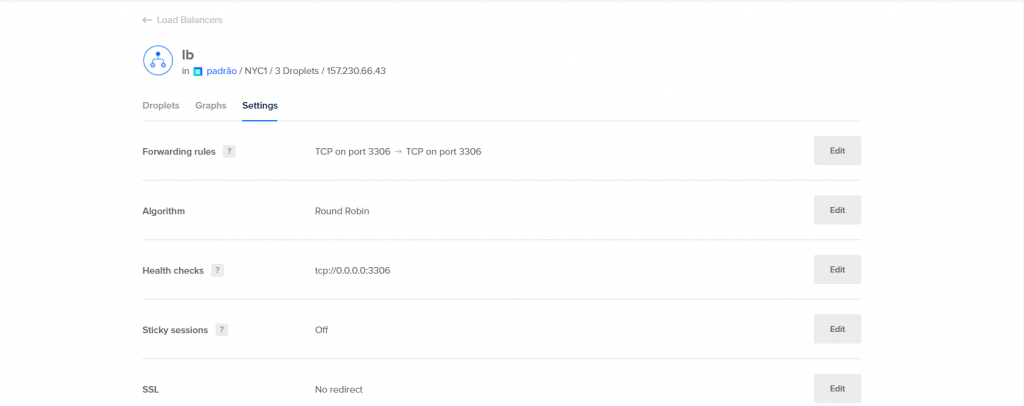
Abaixo você pode conferir os droplets e a configuração de health check que eu coloquei no balanceamento de carga.
A topologia
Baseado nos nomes dos droplets criados na Digital Ocean, a estrutura do cluster vai ser definida da seguinte forma.
db1 = Cluster Control que vai agir como um facilitador de deploy e central de monitoramento do cluster.
db2, db3 e db4 = Cluster galera com réplicas master/master (todas podem fazer escrita e leitura).
Balanceador de carga – Serviço de balanceamento de carga da Digital Ocean
O diagrama pode ser visto na imagem abaixo.
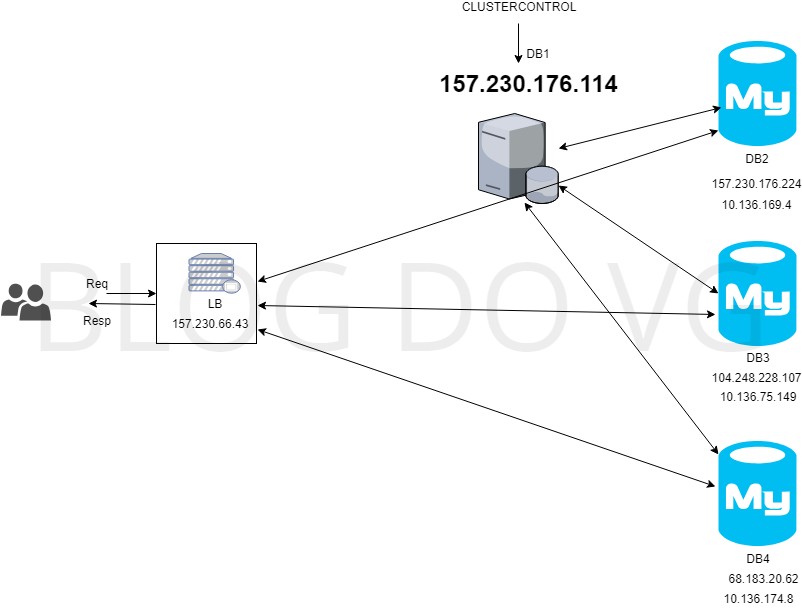
Reparem que neste setup, se a máquina onde está instalado o Cluster Control cair, o cluster continua funcionando normalmente, nas imagens dos bancos o IP de cima é o IP público, e o IP de baixo é o IP privado que os droplets dentro de uma mesma região podem usar pra se comunicar dentro da rede.
Mãos na massa
A primeira coisa a fazer é conectar em todas as máquinas e rodar um update, no CentOS o comando é “yum update” mesmo, em Debian é “apt-get update”, depois disso o próximo passo é logar na máquina db1 via SSH e instalar o cluster control, para isso eu vou usar o nosso amigo putty, uma vez logado na máquina como root ou um usuário com permissão de sudoer, temos que executar alguns comandos, acesse esse link aqui e a página vai gerar uma licença para você usar, será dado um trial de 30 dias da versão ENTERPRISE, após esse tempo a sua versão muda pra COMMUNITY.
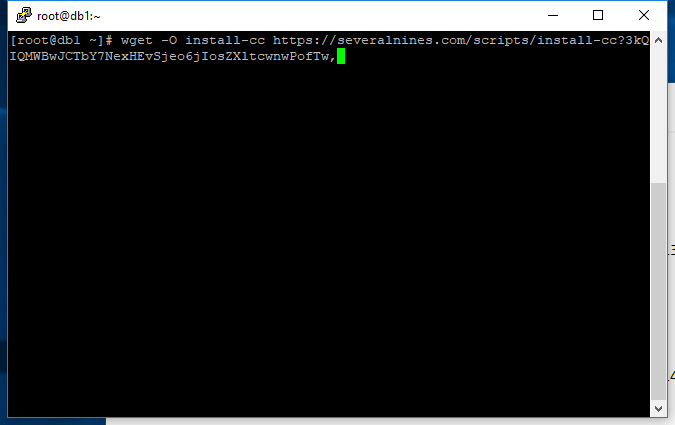
Quando você entrar na página pra baixar o cluster control ela vai te dar alguns comandos para executar a instalação com a sua licença temporária, os comandos vão ser algo como:
wget -O install-cc https://severalnines.com/scripts/install-cc chmod +x install-cc ./install-cc
Execute-os na máquina e a instalação deve começar.
Obs: Caso a sua instalação seja MINIMAL, pode ser que você não tenha o wget instalado no linux, nesse caso ele pode ser instalado via comando “yum install wget” ou no caso de linux baseado em Debian “apt-get install wget”
Se a instalação perguntar se você deseja mudar o ip/hostname da instalação responda “N”, será perguntado também se você aceita enviar dados anônimos de uso para a equipe do Cluster Control, responda com “S” ou “N”.
A instalação vai pedir o password do root, como o Cluster Control está instalando o MYSQL do ZERO basta apertar enter para informar a senha vazia.
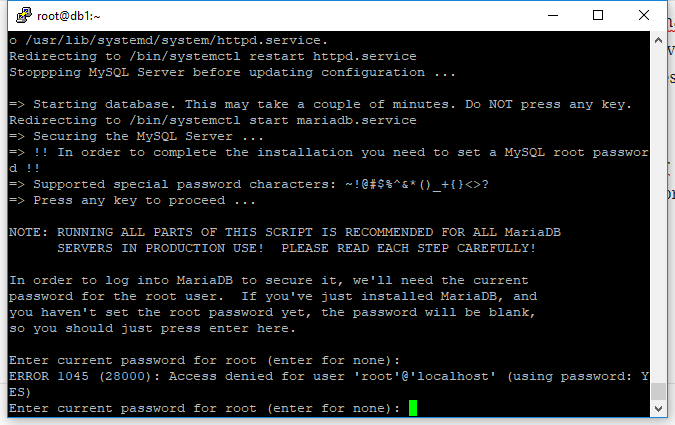
Logo após ele vai perguntar se você quer setar um password para o usuário root, é altamente recomendável que você coloque uma senha para o root, caso já esteja montando ambiente para PRODUÇÃO coloque uma SENHA DIFÍCIL com letras, números e se possível, com símbolos.
A instalação também vai perguntar se você deseja desabilitar o login remoto de root, ou seja, para fazer qualquer procedimento de banco de dados como root será necessário estar logado direto na máquina, usar uma VPN para a rede da máquina ou criar algum outro usuário com privilégio de DBA e dar permissão para acesso remoto nesse usuário, aqui você pode agir conforme sua necessidade.
Outra pergunta que a instalação vai te fazer é sobre a senha do CMON, esse cara é um serviço que é praticamente o CÉREBRO do Cluster Control, ele controla a automatização de tarefas, gerenciamento, monitorando e agendamento de tarefas, depois da instalação concluída você deve ver uma telinha parecida com a tela abaixo, obviamente com um ip diferente.
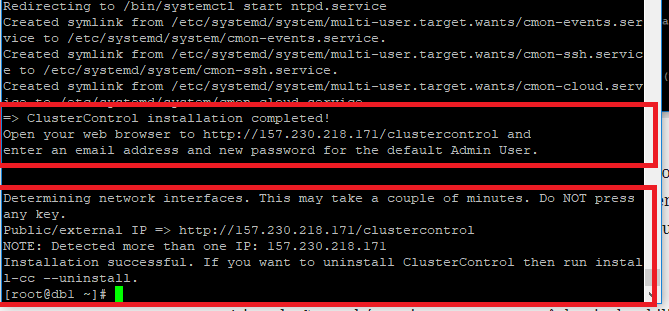
Acesse o endereço informado, informe se deseja ganhar os 30 dias de trial da versão ENTERPRISE, coloque o seu e-mail e senha e logue no sistema, feito isso você vai ver uma telinha bonita tipo essa daqui.
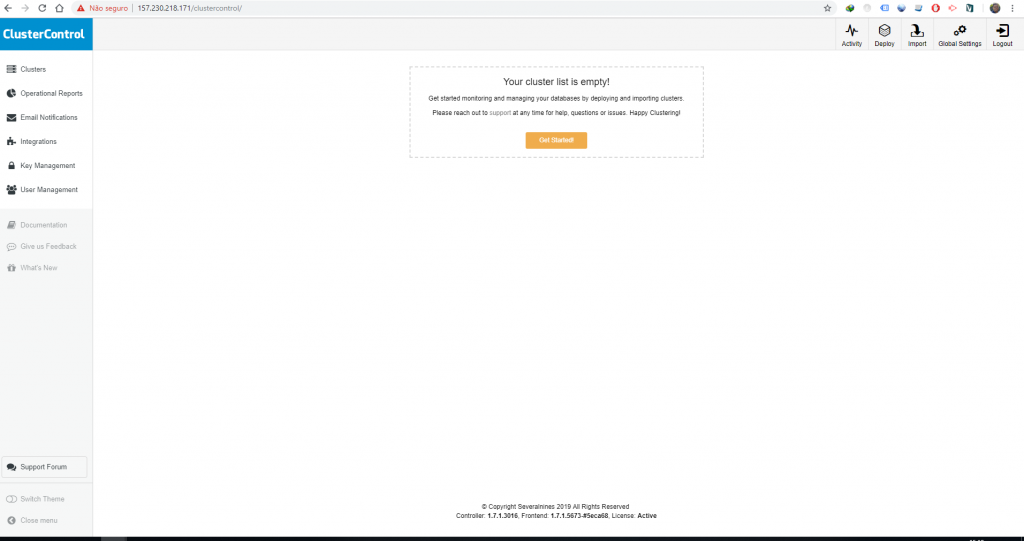
Aee garoto pimpão, agora você já tem o Cluster Control instalado, você é “BIXÃO MEMO” ein mano, PARABÉNS!
GRANDES BOSTA, não tem nada pronto ainda, ainda temos que fazer o deploy do cluster, comunicação entre as máquinas e tals, enfim, baixa essa bola, para de se “O DEVOPS MAIS FODA DO MUNDO” e segue o resto do post.
O nosso próximo passo é garantir que a máquina do Cluster Control possa acessar todas as máquinas que fazem parte da stack sem necessidade de login, para isso vamos usar chave SSH.
Na máquina em que instalamos o Cluster Control (db1) vamos criar nossa chave SSH com o comando abaixo.
ssh-keygen -t rsa
Nas perguntas que ele fizer, simplesmente aperte ENTER, depois disso é necessário copiar essa chave para as outras máquinas, é necessário fazer este procedimento em todas as máquinas incluindo a própria máquina onde a chave foi gerada, utilize os comandos abaixo, lembrando de modificar para os seus ips:
ssh-copy-id root@157.230.176.114 ssh-copy-id root@157.230.176.224 ssh-copy-id root@104.248.228.107 ssh-copy-id root@68.183.20.62
Cada vez que você executar o comando ele vai pedir a senha do root da máquina destino que você está copiando a chave, depois de executar em todas as máquinas é necessário verificar se ficou tudo OK, podemos fazer um teste listando um diretório por exemplo, para isso basta usar o comando
ssh root@157.230.176.224 "ls /root"
Faça isso para cada um dos ips para se certificar que está tudo OK e que o Cluster Control não vai ter problemas para acessar as demais máquinas da nossa Stack.
Com estes passos concluídos o resto da brincadeira vai acontecer no Cluster Control, acesse o endereço do painel de gerenciamento (o endereço que apareceu no final da instalação, mas basicamente é ipdamaquina/clustercontrol ) e vamos criar o nosso cluster.
A primeira coisa que eu gosto de configurar é o SMTP, com isso vamos receber alertas das atividades que o Cluster Control realiza.
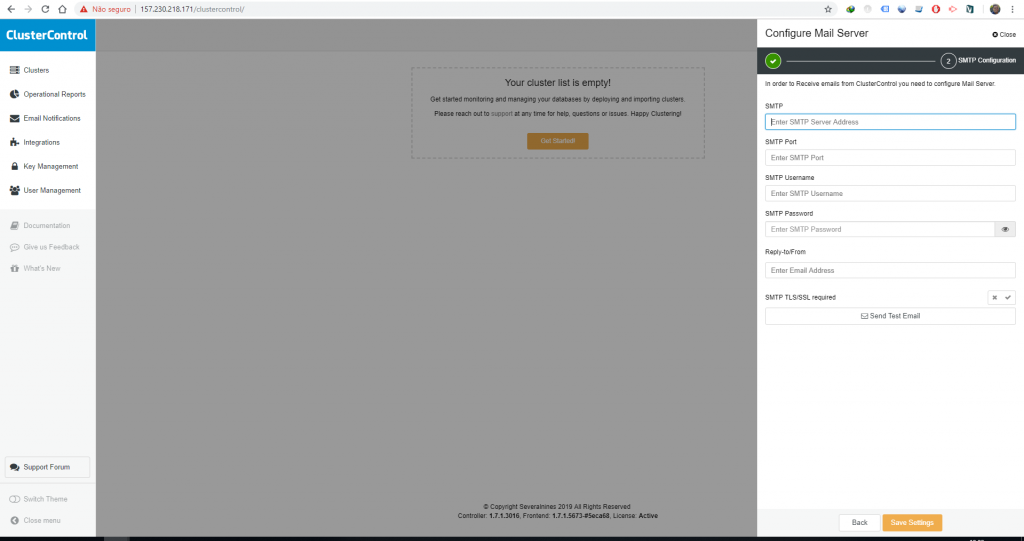
Depois disso, clique em Deploy no canto superior direito, na tela Welcome, clique em Deploy novamente, com isso será exibida seguinte tela.
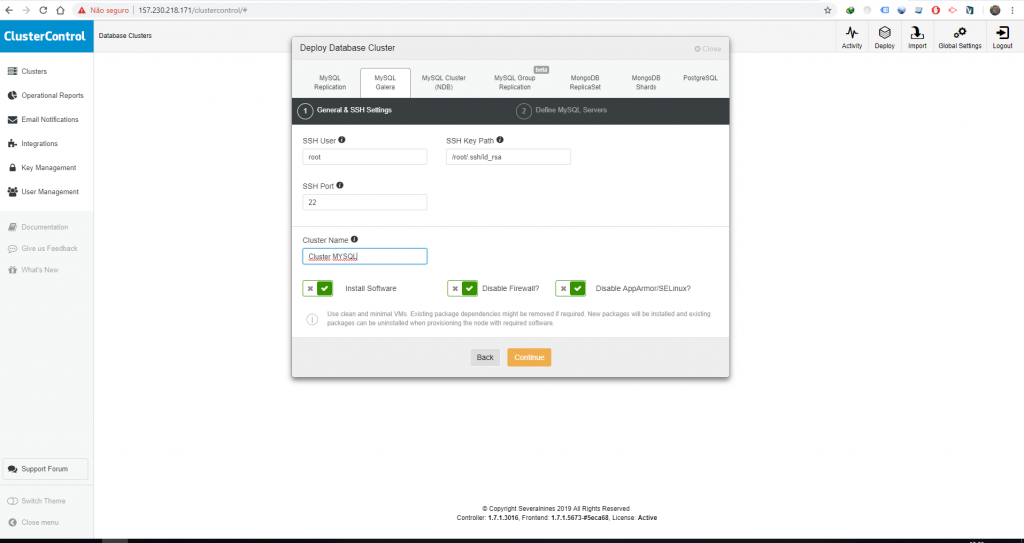
Os campos são autoexplicativos, mas basicamente o usuário é o usuário de sistema que vai executar os comandos na máquina, o SSH Key Path é preenchido automaticamente, de resto temos a porta SSH e demais opções para o Cluster Control funcionar corretamente. Como já deu pra perceber, o nosso cluster vai utilizar o Galera Cluster.
Ao clicar em Continue você vai se deparar com outra tela.
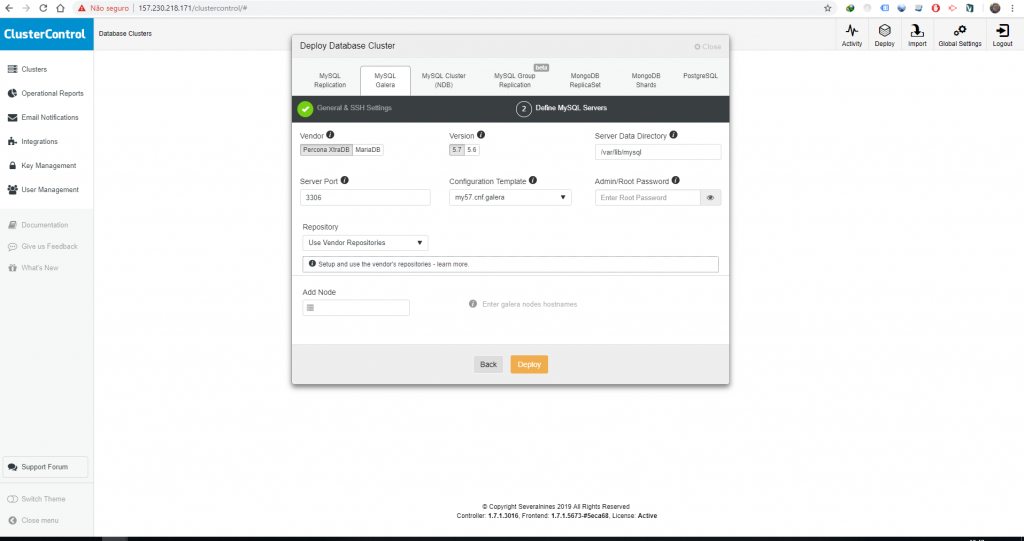
Nessa tela devemos configurar o password do usuário root do MYSQL, este usuário será criado em todos os nós, para selecionar quantos nós vamos querer usar basta inserir seus IPs na parte de baixo, em Add Nodes. Aqui cabe um comentário, se você estiver usando private network do computador onde está o Cluster Control com os demais computadores que vão ser os clusters do banco de dados você pode inserir apenas o IP privado (lembrando que caso queira acessar de fora é necessário usar o IP externo, desde que o usuário tenha permissão para acesso remoto).
O ideal é não ter todos os ovos dentro do mesmo cesto, ou seja, se quiser realmente ter ALTA DISPONIBILIDADE no seu cluster não use máquinas (por máquinas você entende VPS/Bare Metal, etc) de uma mesma região, use uma em NEW YORK, outra em DALLAS, outra em CHICAGO e assim por diante, utilizar provedores diferentes (RAMNODE, SSDNODES, VPSDIME) também é uma possibilidade, mas obviamente tem o fator latência a se considerar, usando máquinas de um mesmo provedor essas máquinas mesmo que em localidades diferentes provavelmente terão um bom tempo de resposta entre elas.
No meu caso eu vou utilizar os IPs internos das máquinas, os meus nós do cluster serão os droplets db2, db3 e db4, com isso minha configuração vai ficar assim, depois de adicionar os IPs se aparecer o ícone verde significa que a máquina está acessível para o Cluster Control.
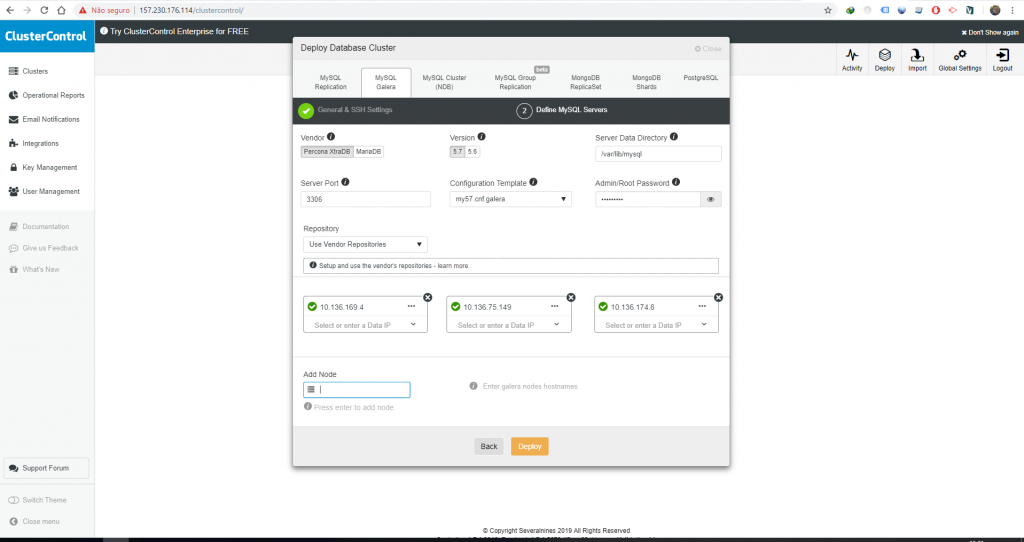
Agora é clicar em Deploy e esperar o cluster ficar pronto, esse processo depende da configuração das máquinas em termos de rede e recursos e para esses 3 nós costuma demora entre 10 e 20 minutos, variando para mais ou menos dependendo da configuração e velocidade da rede.
Uma das coisas legais do Cluster Control é que você pode acompanhar o andamento dos Jobs que ele executa, caso queira acompanhar o deploy do cluster basta clicar em Activity no menu superior direito, depois ir em Jobs e finalmente em Running, você deve ver uma tela semelhante a essa.
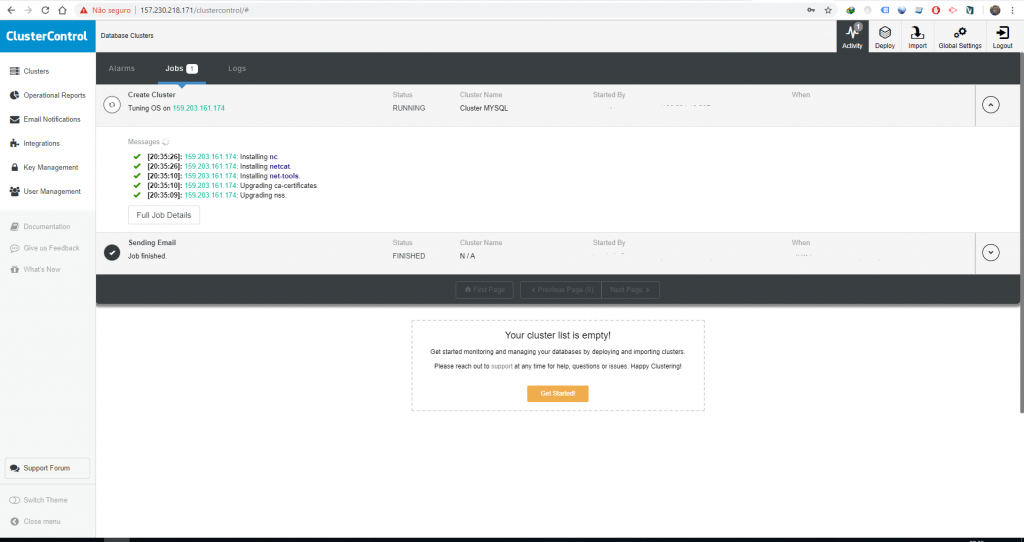
Depois de concluído o processo, ao clicar em Clusters você deve ver essa tela bonita aqui.
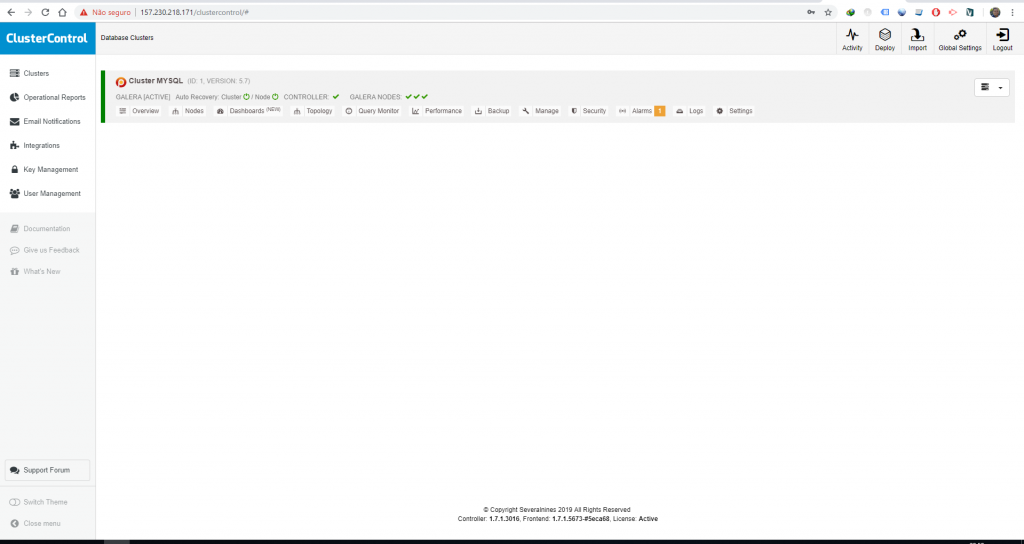
Importando banco de dados
Antes de seguir adiante nós temos duas opções aqui, importar um banco de dados existente ou criar um banco de dados novo, caso estejamos fazendo migração podemos importar o .sql do banco de dados exportado, caso contrário podemos criar um banco de dados novo direto no Cluster Control, para este exemplo eu criei uma banco de dados com a tabela pessoa em um servidor MYSQL local.
A base e a estrutura da tabela eu criei na mão, depois disso eu importei 110000 linhas pra ela usando o site http://filldb.info, caso queira baixar este arquivo exemplo pode pegar aqui.
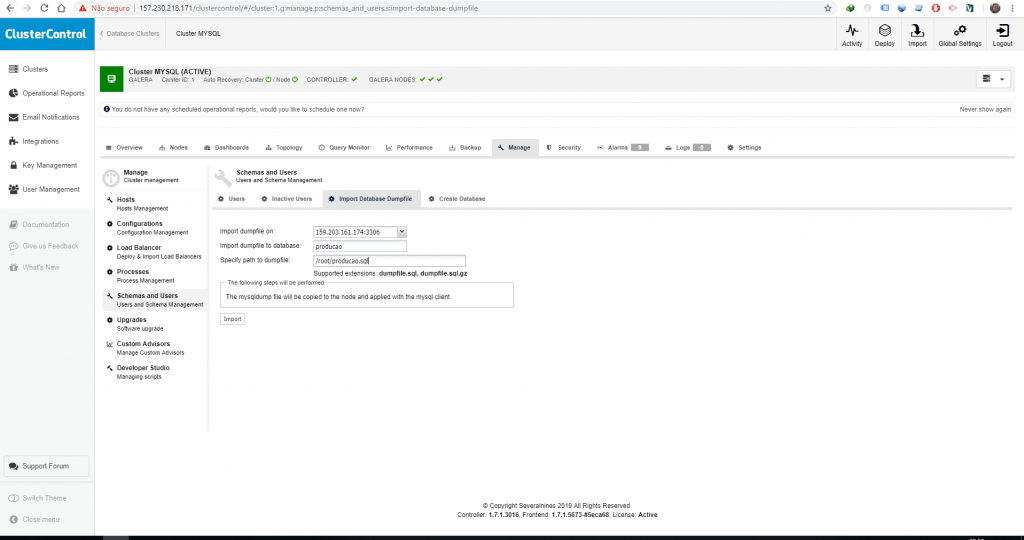
Para importar este arquivo no cluster ele deve estar dentro da máquina que está rodando o Cluster Control, no meu caso eu coloquei o arquivo (producao.sql) dentro do diretório /root, então o caminho do arquivo ficou /root/producao.sql.
Para importar um .sql no Cluster Control vá no menu do lado esquerdo, opção Clusters e escolha a opção Manage, Depois vá em Schemas and Users, clique na aba Import Database Dump File.
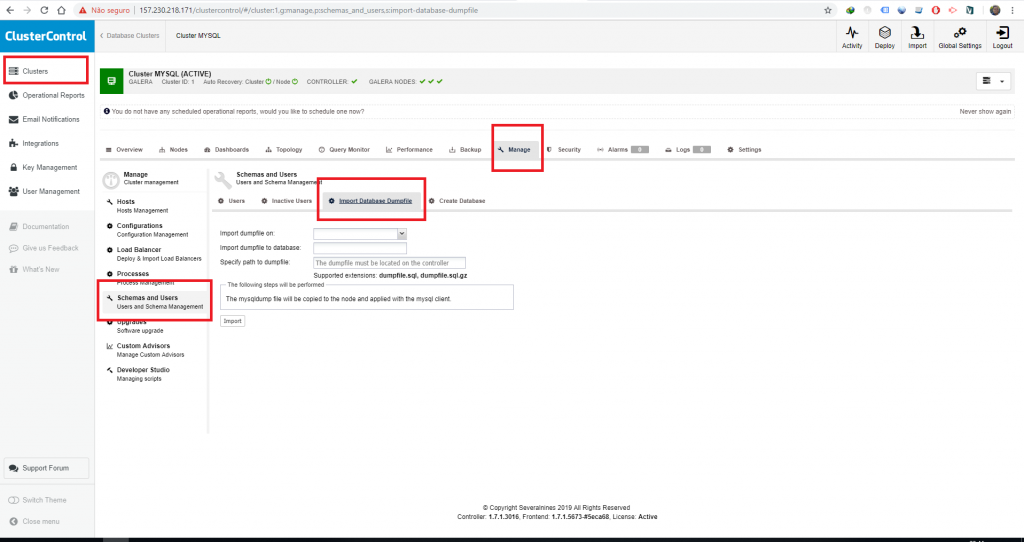
Depois é necessário informar para qual nó o arquivo será copiado, o nome do banco de dados que será criado, e por fim o caminho do arquivo, depois de copiado o arquivo será executado e replicado para todos os nós do cluster.
Testando replicação
Depois que a importação for realizada com sucesso é necessário criar um usuário de banco de dados para fazer um teste, para fins de exemplo vou criar um usuário que conecta externamente e com acesso em todas as bases.
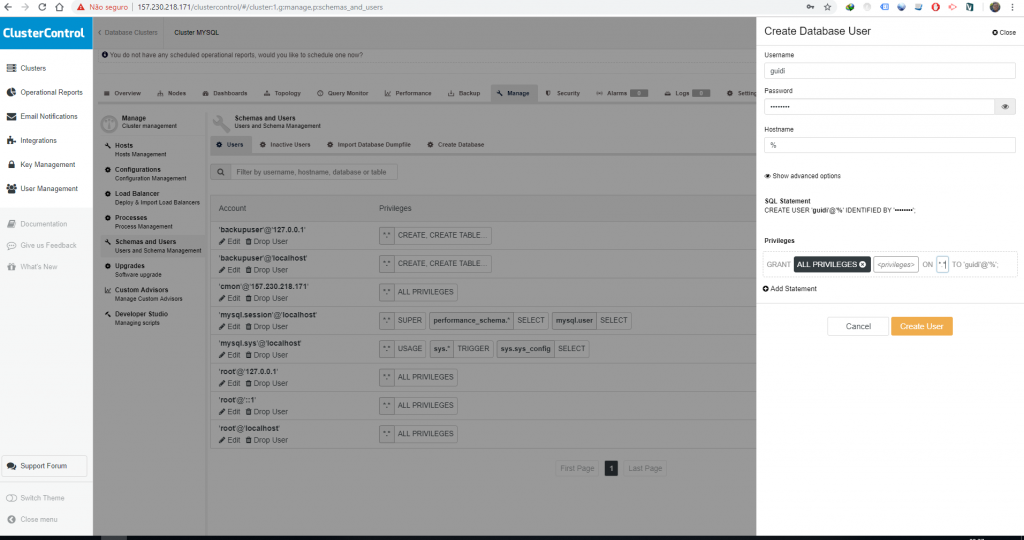
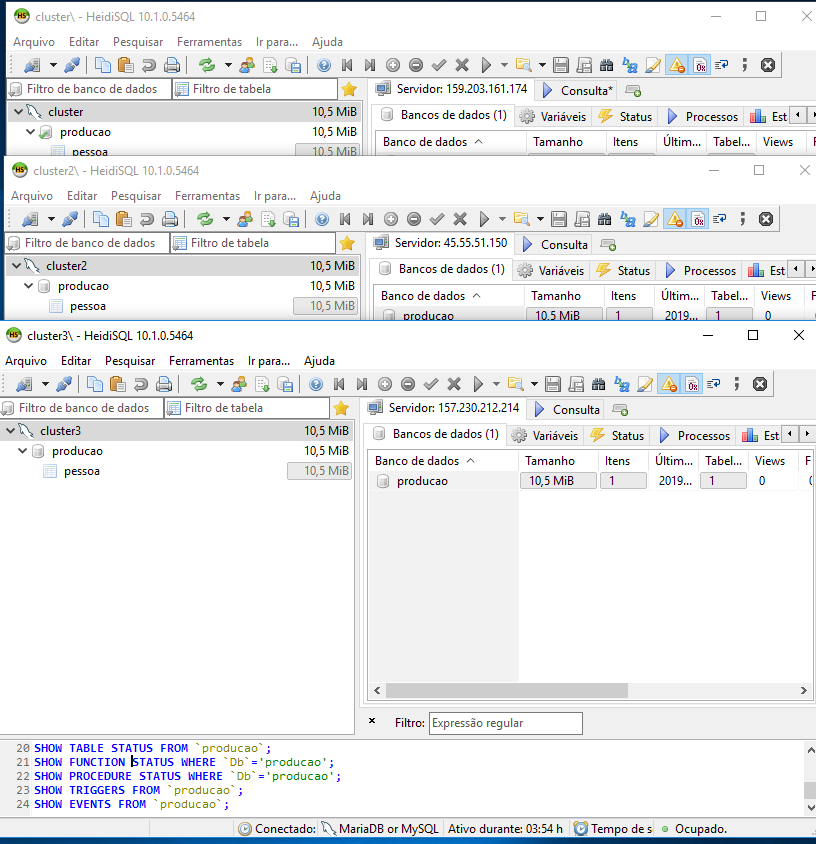
Com isso esse usuário consegue acessar automaticamente (especificado através do % na criação do usuário) todos os nós do cluster, ao conectar nas 3 máquinas separadamente podemos ver que existem os mesmos dados em ambas.
E ao fazer o INSERT em uma delas, podemos ver que o dado é replicado para os outros nós do cluster.
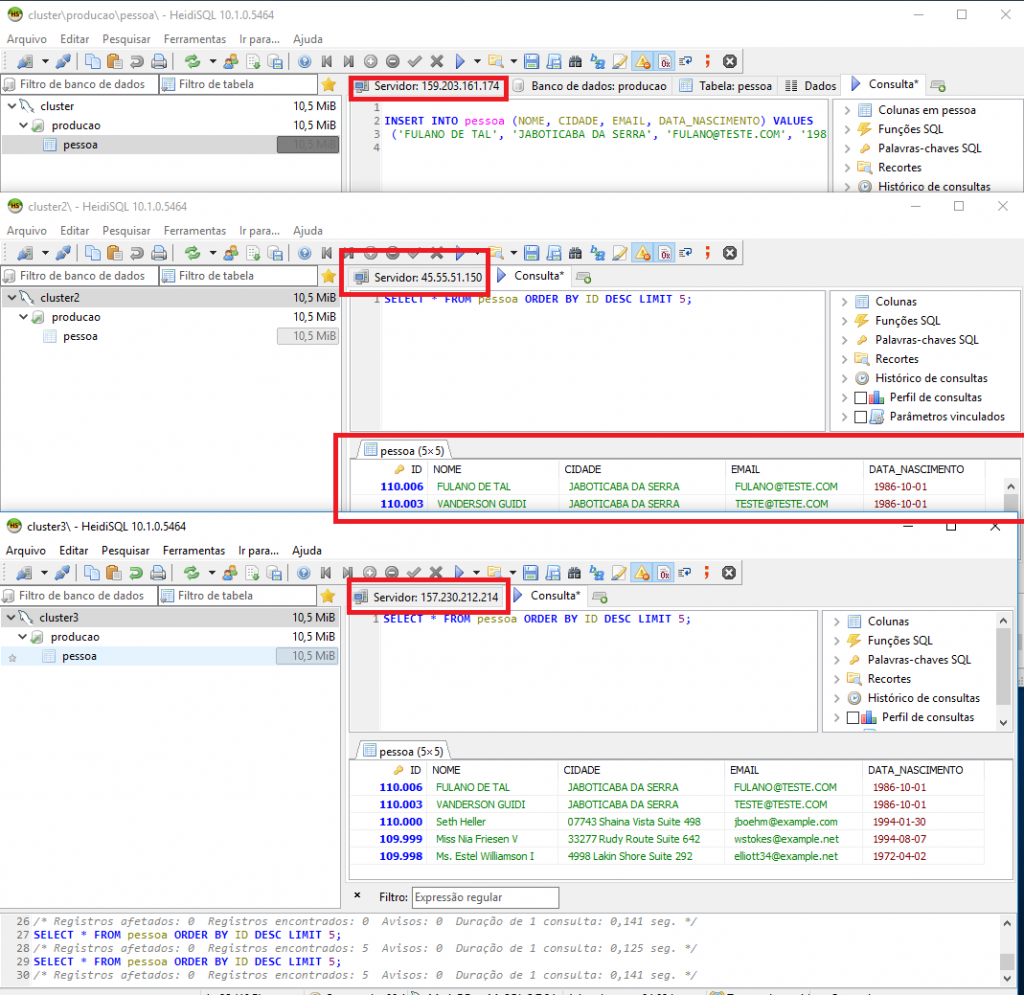
Você, dev maroto que é deveras observador e atento aos detalhes deve ter percebido que o ID da tabela pessoa dos dados que foram inseridos estão pulando de 3 em 3, isso acontece devido ao fato de estarmos trabalhando com 3 nós master no cluster, ou seja, todos eles permitem ESCRITA e LEITURA e para não dar conflito de chaves o Galera adiciona um incremento para cada nó existente, ou seja, se tivessemos 4 nós ao invés de 3 no nosso cluster o sequencial estaria pulando de 4 em 4 ao invés de 3 em 3, para saber mais basta ler este post aqui.
Habilitando a dashboard com Prometheus
Bom, já vimos que a parte de replicação está funcionando como deveria, o nosso próximo passo é habilitar a dashboard para poder acompanhar melhor o cluster, para isso vá no menu Clusters do lado esquerdo, clique em Dashboards e depois clique no botão Enable Agent Based Monitoring.
Na parte de seleção do Host em que será instalado o Prometheus Server eu recomendo instalar na máquina onde está o Cluster Control.
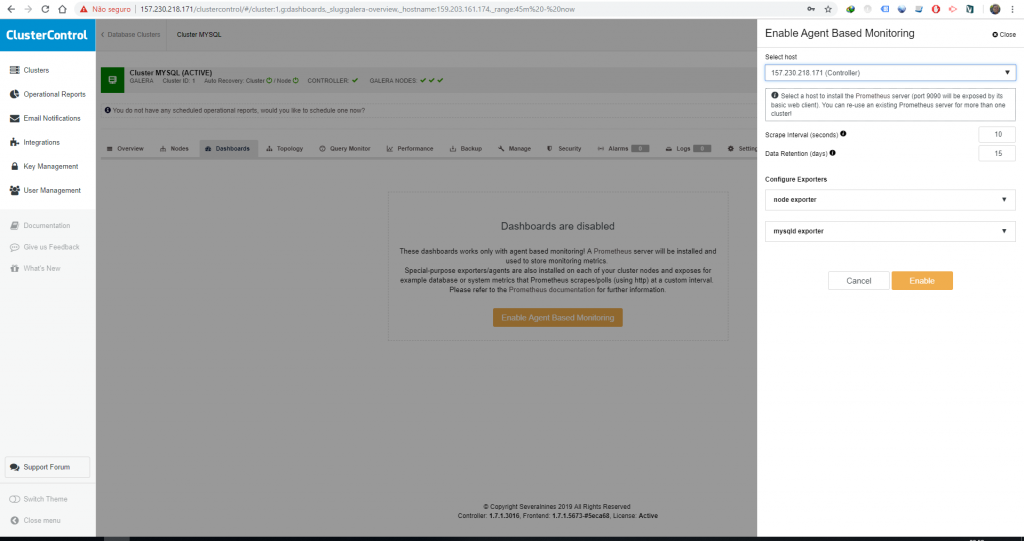
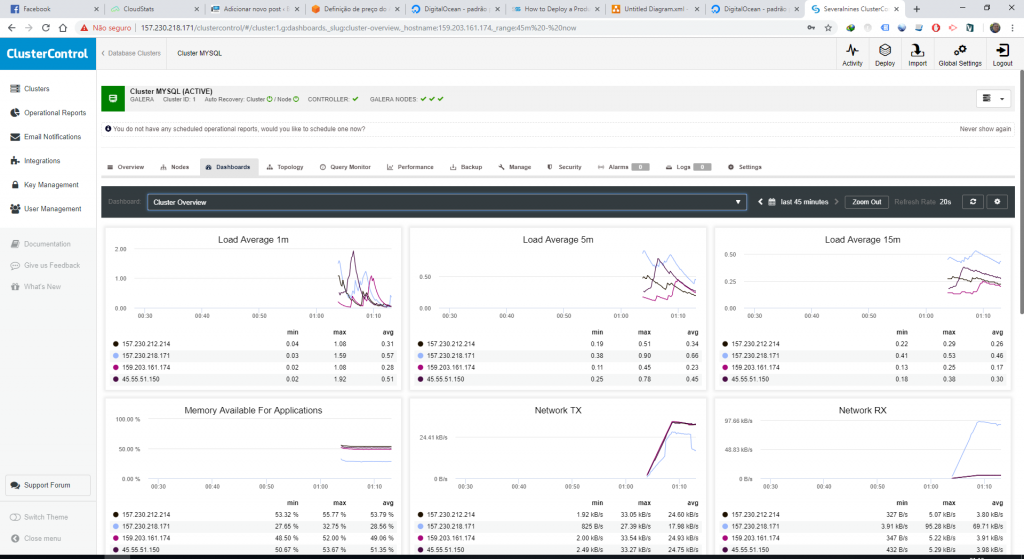
Depois disso vamos ter a dashboard disponível, além das informações que o próprio Cluster Control já fornece, dê uma futucada pra conhecer melhor.
Agendando os backups
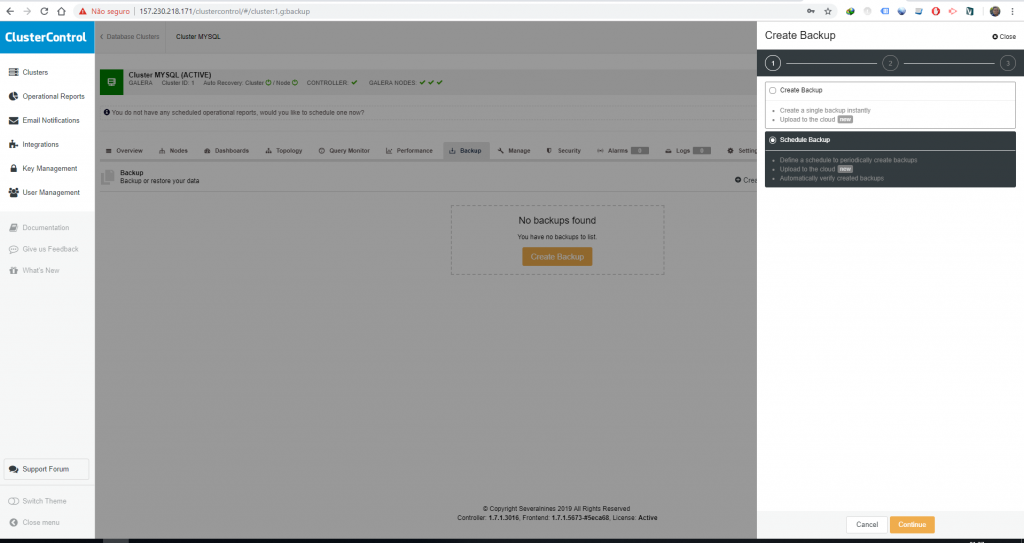
O nosso próximo passo é agendar os backups, para isso basta acessar a opção Clusters do lado esquerdo, Backups e depois clicar em Create Backup.
Nessa nova janela você terá a opção de criar um backup no momento ou criar agendamento de backup, nós vamos criar o agendamento de backup.
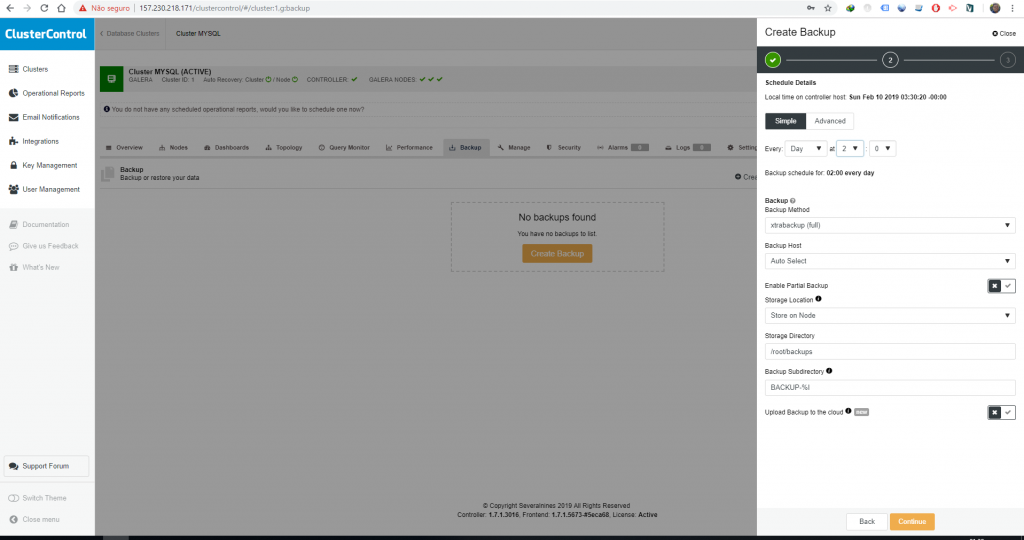
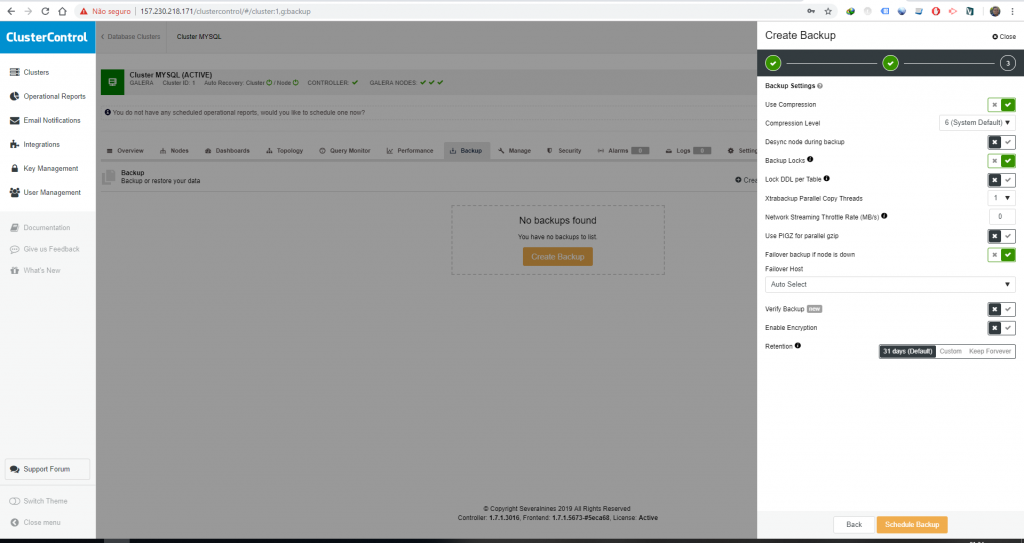
Nessa tela você vai poder escolher o método de backup, periodicidade, se ele vai ser incremental, onde ele vai ser salvo e se for o caso escolher um provedor de nuvem para salvar esse backup.
Configurando o balanceamento de carga
Hihihi, nessa etapa aqui não precisamos configurar nada, pois o balanceamento de carga está sendo feito pelo Load Balancer que criamos lá no início do tutorial, o Health Check está sendo feito com uma conexão na porta do MYSQL (3306) e o algoritmo que estamos utilizando é o Round Robin, o Load Balancer nesse caso nem precisaria ser da Digital Ocean, poderia ser qualquer outro como o da CloudFlare por exemplo, a vantagem de usar o da Digital Ocean é que por estar dentro da rede ele pode acessar as máquinas e direcionar o tráfego muito mais rápido, uma coisa interessante a se fazer é colocar o ip do Load Balancer atrás de um domínio, algo como db.meusite.com.br, isso pode ser resolvido de forma fácil criando um registro A no DNS do seu domínio.
Abaixo podemos ver uma imagem do status do balanceamento do Cluster.
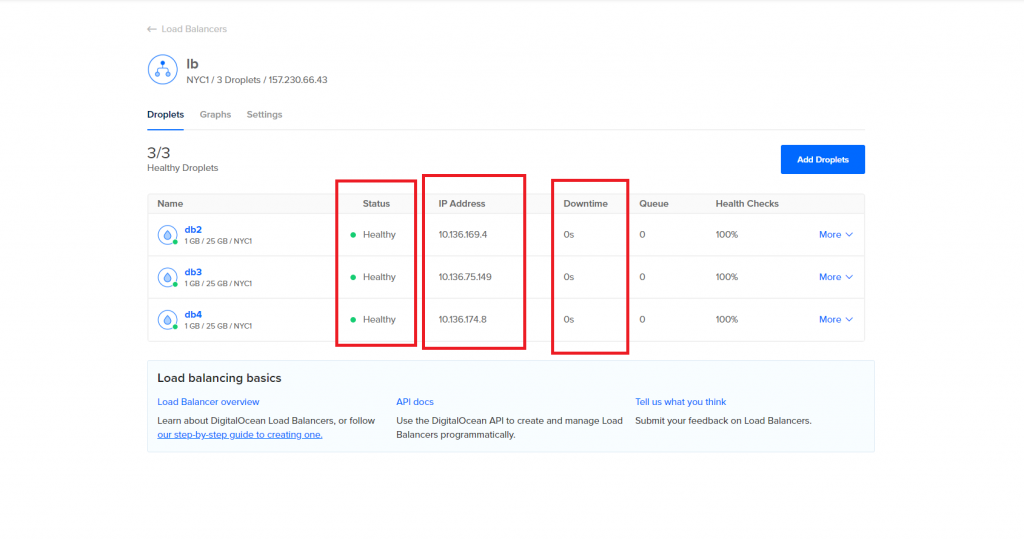
Para conectar no banco de dados eu posso acessar direto pelo ip do balanceamento e o balanceamento vai me redirecionar para alguma instância que esteja saudável ou posso conectar direto em uma instância pelo seu IP, uma boa prática é restringir via IPTABLES o acesso externo direto nas instâncias e deixar que o acesso seja feito apenas via balanceador, os únicos IPs que eu vou deixar acessar a instância direto são os IPs do Cluster Control, para fazer isso, logue em cada uma das máquinas do cluster (db2, db3 e db4) e execute o seguinte comando (não esqueça de alterar o IP).
iptables -A INPUT -p tcp -s 157.230.176.114 --dport 3306 -j ACCEPT iptables -A INPUT -p tcp -s 10.136.157.203 --dport 3306 -j ACCEPT service iptables restart
Para fins de teste eu vou propositalmente desligar o droplet db2 e ver como fica o status no balanceamento.
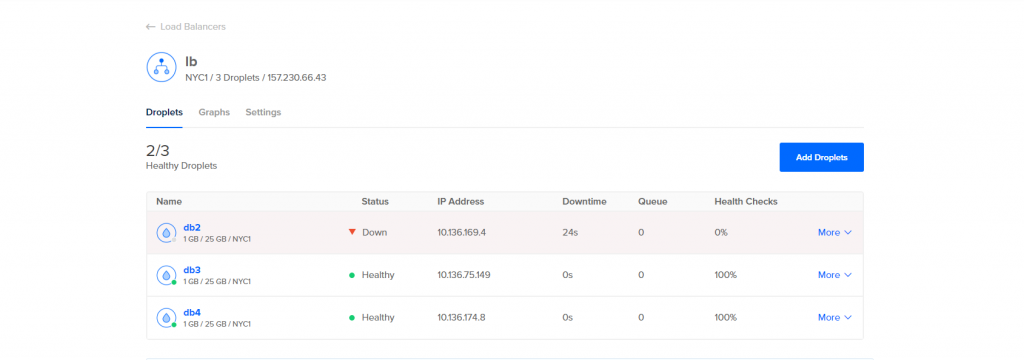
Mesmo com o db2 fora eu consigo conectar normalmente pelo IP do balanceamento e fazer operações no banco de dados, quando o db2 volta a ficar operacional ele pega todas as alterações que foram realizadas e fica integro com os demais nós do cluster, o Cluster Control também te envia e-mail de alerta informando que o nó está fora.
Existe um outro tipo de balanceamento que envolve mais duas máquinas, um ip virtual, ProxySQL e KeepAlived mas isso é assunto pra outro post (que sairá só Deus sabe quando).
Cabe salientar que caso você queira fazer um deploy master/slave (apenas um nó tem permissão para escrita e leitura, os demais são somente leitura, uma boa opção para aplicação com muitos relatórios ou dashboards ) de POSTGRESQL isso pode ser feito com apenas alguns cliques, o processo é bem parecido com o Deploy do MYSQL, fora isso você ainda tem a opção de cria um cluster de MongoDB, nada mais nada menos que o melhor banco NOSQL que existe.
Então é isso, vou ficando por aqui e até a próxima, qualquer dúvida manda aí embaixo, no twitter ou no facebook que eu respondo assim que possível, ou não…